WIL: A Compiler Intermediate Language with Explicit Support for Representations
Tapan S. Parikh
Quals Paper
March 5th, 1999
Abstract
Many high-level object-oriented languages such as Java, Cecil and Smalltalk provide a uniform data model where all data values can be viewed as implicitly heap-allocated, garbage-collected pointers to data with header information common to all values. This abstraction has numerous benefits, as it provides the programmer a uniform view of object behavior and semantics, and allows simple expression of shared state. However this data model can have significant performance consequences due to increased memory traffic, poor data locality and increased overhead in memory management.
This work seeks to avoid these pitfalls by retaining the uniform data model in the source language semantics while pursuing representation optimizations where possible in the implementation. This is done by allowing the source language front-end to annotate all data values with representations, which can be specified at the abstract level, thereby specifying only the high-level semantics of the value. This allows later stages of compilation to make concrete implementation choices that define its layout in memory and the implementation of all operations upon it. In the course of making such choices, the optimizer may choose to perform layout optimizations that can potentially improve performance, such as inlining a pointer field. Since these optimized representations may not always support the precise semantics intended for the source-level value, the compiler must ensure that these optimizations are safe, possible and profitable. The optimizer can be guided by source-level directives, data flow analysis and profiling data to help make these decisions.
We present a representation specification language that is a subset of our compiler intermediate language WIL. This is used in a framework for representation choices and code generation called representation lowering that allows a declarative specification of default representation choices and optimizations. We also describe some example optimizations that can be performed using the proposed system.
1. Introduction
WIL is a textual compiler intermediate language designed primarily for object-oriented languages, to be used in the Whirlwind compiler being developed at the University of Washington. WIL is intended to be language independent, and can be used as a target language for front-end compilers from a number of higher level languages. The preliminary design of Whirlwind includes plans for front-ends for Java, C++, Smalltalk and Cecil, but the list of possible high-level object-oriented languages suited for translation to WIL is by no means limited to this list.
One of WIL’s main contributions is the explicit support for representation specification in the intermediate language. A representation is a description of a data value. It specifies the possible operations upon the value, as well as the intended semantics of these operations. An abstract representation only specifies the high-level behavior for a value, while a concrete representation also specifies the physical layout of the value in memory, as well as the implementation of all supported operations. WIL contains a representation specification language that allows the description of a variety of abstract and concrete representations.
The source language front-end will generate an intermediate WIL file where each data value is annotated with a particular representation. This representation can be either partially or fully abstract, which allows the ability to defer decisions about the concrete bit layout of some or all of the value’s contents to later stages of compilation. Generally each data value will start with an abstract representation, which will in turn go through a sequence of lowerings as representation choices are made. These lowerings will eventually transform both the representation and the operations upon it to fully concrete forms, down to the level of the actual bit layout of the value in memory, allowing for easy low-level code generation.
This framework allows the optimization phase of the compiler to choose more efficient layouts for data values where possible. When choosing an alternate representation for a value, the compiler infrastructure must ensure that the value's intended semantics are not changed. Some important properties of values that must be maintained through transformation include sharing relationships between objects, pointer equality and assignment semantics. All operations on the transformed value must maintain the semantics intended for the original high-level representation. In short, the compiler must verify that all proposed optimizations are possible, safe and profitable. The compiler can rely on sophisticated data flow analysis, gathered profile data and programmer annotated directives to help make this decision.
Some examples of possible layout optimizations include more efficient representation of header words, tighter bit packing, cache-conscious data structures and removing levels of indirection through pointer dereferences. This last opportunity for optimization is particularly important, especially in many current object-oriented languages that have a uniform pointer-based model of data and references. Such languages include Java, Smalltalk, Cecil, ML, Lisp and Scheme. The advantages of this pointer-based approach include simplicity and uniformity, but with significant performance cost. In contrast, a lower level language like C++ has a more complicated and error prone data model, but remains the language of choice for many applications due to better efficiency. This work hopes to provide the best of both these worlds by providing a simple uniform data model in the source language semantics while retaining the efficiency of lower level languages by pursuing safe and beneficial layout optimizations where possible.
The rest of this work is organized as follows: Section 2 gives a brief description of the WIL language, Section 3 gives some motivation for pursuing representation optimization, Section 4 describes the representation specification subset of WIL and Section 5 describes the process of code lowering and optimization. Section 6 describes some possible layout optimizations using this framework and Section 7 describes some related work in representation specification and optimization. Section 8 concludes our approach, and Section 9 presents the status of the project and future work.
2. Overall Design of WIL
The following is intended as a brief overview of the basic syntax and semantics of WIL, followed by a more detailed exposition of the representation specification features, which is the focus of this work. Please refer to the WIL grammar, found in Appendix A, as a reference.
WIL allows for the construction of data values of a number of distinct types, including string and numeric literals, arrays, records, unions, pointers, anonymous functions, generic functions and classes. Expressions are built of the constructed data values, and associated operations possible on these values. Possible operations include function application, field indexing, array indexing, union projection, pointer dereference and a number of unary, binary and comparison operators. Only certain operations are applicable to each data type. An identifier can be assigned to the result of any such expression. An identifier can be declared as immutable, which means it can not be updated again.
Each identifier and constructed value is annotated with a particular representation. In addition, each operation can be specialized to operate on and produce certain representations. It will be up to the compiler front-end to ensure that appropriate representation conversion operations are inserted where the representations do not match on two sides of an assignment statement, or where a certain operation is not supported on the given representation. A thorough description of the representation language and it’s proposed implementation will be given in the following sections.
WIL also provides a number of common control structures, such as conditional branches and switch statements. It also supports arbitrary labels and goto statements, with optional parameters. This is hoped to eventually allow a general mechanism to specify non-local returns and exceptions. WIL also provides a common framework for method dispatching, combining single, multiple and predicate dispatching under a single, unified semantics [8]. This is supported by the creation of generic function objects, to which individual method cases are added. Each individual method case contains an associated function body, as well as a predicate that will determine whether or not the case is applicable on a particular invocation. The predicate can be a class or subclass test, the evaluation of an arbitrary run time expression, or the conjunction, disjunction or negation of other predicates. Each generic function also defines a calling convention, in terms of the representations of the parameters and result, which all method cases must adhere to. This allows callers to ensure that the actual parameters match the function calling convention.
The following is a short code example that displays the versatility and conciseness of the WIL intermediate language. A generic function named distance is declared which implements the distance function for a hierarchy of Cartesian points. The method case implementing distance for two dimensional points is attached to the generic function, and is defined via a method body. The defined distance method takes two parameters, each a two-dimensional Cartesian point, and returns a real number, the Cartesian distance between the two points. Representations for generic Objects and 2Dpoints are named, and each value in the program is annotated with a representation. The details of the representation specifications will be described in a later section.
rep Object := *Record {class: class, ... };
rep 2Dpoint := *Record {class: class, x: Integer, y: Integer};
decl distance := gf (Object, Object): double
method distance(point1: 2Dpoint, point2: 2Dpoint): double
when (point1.class @< 2Dpoint) and (point2.class @< 2Dpoint)
{
decl result:double :=
sqrt((point1.x-point2.x)*(point1.x-point2.x) +
(point1.y-point2.y)*(point1.y-point2.y));
result;
}
Figure 1: An example of WIL code
3. Motivation for Explicit Representations in WIL
Many current object-oriented programming languages take advantage of the inherent simplicity of a uniform pointer-based data model. All data values in such languages are heap-allocated, garbage-collected pointers to data, with a uniform header layout that contains fields common to all values. This provides the programmer with a uniform view of object behavior, as all values can be viewed as references with a common interface, often referred to as a boxed representation. This allows the semantics for assignment and identity to be the same for all values. This abstraction also makes it particularly easy to support polymorphism, since the common object interface makes it less important to know the precise type of a value. Additionally, objects can easily share state via common references. This type of data model is prevalent in most high-level object-oriented languages, including Cecil, Smalltalk and to a certain extent Java.
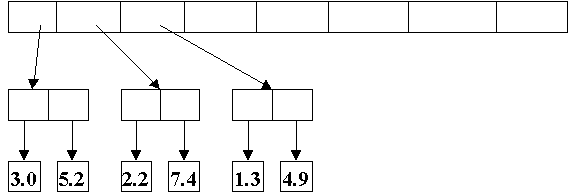
Regardless of the benefits, the cost in efficiency in a uniform pointer-based object model can be quite high. For example, consider the case of the representation of an array of complex numbers, a common data type in numerical computations (figure 2).
Figure 2: An array of complex numbers in Smalltalk
Each element in the array is a pointer to a complex number structure, each field of which is in turn a pointer to a floating point value. Each component in such a model is implicitly a pointer-based, heap-allocated, garbage-collected reference. In addition, the reference to the array itself is also likely to be a pointer with the same properties. The cost of accessing any one value in this array will include the overhead of three pointer deference operations. The fact that all objects are separately allocated also results in poor data locality, resulting in poor cache and memory system performance and increasing memory traffic. In addition there is also the added overhead of heap allocation and garbage collection for all values. This inefficiency can lead to a performance degradation up to an order of magnitude in certain numerically intensive calculations [3]. Often this cost is prohibitively high, and dictates the use of a more flexible programming language.
Complex lower level languages such as C++ (and a certain subset of Java) give the programmer more direct control over the physical implementation of each data value. This allows fine grained control of the precise semantics of each individual field and variable. Each field or variable can be declared either as a pointer or as inline, declarations which can be mixed arbitrarily within compound data types. Additionally, memory can be allocated either on the stack or on the heap, with different memory management protocols. This leads to many complications for the programmer, who has to keep track of the different semantics of each value, and the different memory management issues involved with stack and heap-allocated data structures. This often leads to many common memory usage errors. This complicated data model has clear drawbacks in terms of simplicity and uniformity, but can often provide significant efficiency improvements over the high-level data model, often up to an order of magnitude in numerically intensive applications [3]. For instance, the same array of complex numbers described above can now be represented completely inline (figure 3).

Figure 3: A possible representation of an array of complex numbers in C++
In this representation each complex number structure is embedded in the array, and both fields of the complex number are embedded values. This saves three pointer references per access, and if the array is stack allocated, will also avoid the cost of heap allocation and garbage collection. This approach also provides much better data locality, significantly improving cache performance. This type of flexibility often dictates the use of lower level but more error prone languages in many applications.
The Java object model is somewhat of a hybrid between these two approaches. In general it seeks to provide a uniform pointer-based object model, where all values are implicitly heap-allocated and garbage-collected. In addition, for efficiency reasons, it provides inline versions of certain often used primitive data types, such as integers, reals and characters (figure 4).
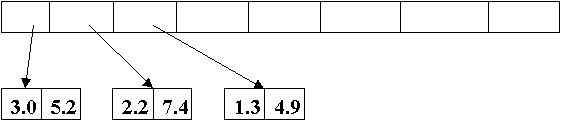
Figure 4: An array of complex numbers in Java
However these values cannot be used with full generality in the language. For example, such values cannot be used in a polymorphic context where a pointer-based value is expected, such as when storing values in a queue. Alternate pointer-based versions of these primitive types must be provided for these purposes. This approach is able to salvage some of the efficiency losses from a uniform object model, but at the cost of added complexity in the source language. Even in this more flexible model the overhead of pointer dereference operations and garbage collection can be quite high [3].
The goal of this work is to provide the programmer a uniform, pointer-based, garbage-collected data model, while at the same time allowing the compiler to pursue aggressive optimizations of data layout that can regain much of the efficiency loss thought to be inherent in higher level languages. Examples of such optimizations include automatic inlining of objects and fields, improved packing of data, and more efficient representations of header fields. Such optimizations should greatly reduce the unnecessary pointer dereference and memory operations that plague such languages. However, since the optimized representations do not always obey the semantics intended for the original value, it is important to determine where such transformations are safe, possible and profitable.
Another possible benefit of a general representation specification and implementation framework is the possibility for added simplicity and modularity in code generation for a variety of different representation types. In such a system, code generation transformations may be described at the meta-level, possibly declaratively, to replace complex code that is ordinarily needed to generate code to access components of aggregate representations. This is done in a language-independent manner, allowing the specification of a variety of source language data models, as well as both general and language-specific layout optimizations. This makes it easier to experiment with different types of layout options and encodings.
4. Representation Specification Syntax in WIL
A representation is a description of a data value. It specifies the possible operations upon the value, as well as the intended semantics of these operations. An abstract representation only specifies the high-level behavior for a value, while a concrete representation also specifies the physical layout of the value in memory, as well as the implementation of all supported operations. WIL has a rich syntax for describing a variety of simple and aggregate data representations, both abstract and concrete. All declared data values, including generic function parameters and return values, can be tagged with one of these representations, essentially serving as type declarations that dictate which operations are possible on a given value. Viewing representations as types, WIL can be considered a typed intermediate language.
Initially, values are usually labeled with abstract representations, which define a set of abstract operations that are possible on a given value. As physical representation choices are made, the value and the operations upon it go through a sequence of lowerings that convert the representation into more and more concrete forms. Finally, when the value’s representation, as well as all operations upon it, become fully concrete, code can be generated based on the final physical layout of the value. The remainder of this section describes the spectrum of representations that can be selected for a given value, while the next section describes how these selections can be used to generate code through a sequence of lowerings.
WIL supports a number of base representation types, including bit vectors, integers and real numbers. WIL also supports the specification of several derived data structures, such as pointers, records, unions and arrays. Most of these representation types have both abstract and concrete versions, which differ in the level of layout specification for the final physical value. In addition, representations can be named and re-used for conciseness. For a full grammar of the representation specification language, refer to the WIL grammar in Appendix A.
Bit vectors can be specified in WIL as an integral number of bits, bytes or words. This specifies the size of the sequence of bits. This is the most concrete representation possible in WIL, and it is imagined that in a full implementation more complex aggregate data types will eventually be lowered to bit vectors, and the operations on these types will also be lowered to corresponding bit vector operations.
There are number of abstract integer representations in WIL. The most general is an arbitrary abstract integer, which corresponds to a conventional integer in most high-level source languages. In addition, WIL also provides the ability to declare a value as an integer constant or as an integer sub-range. This specification can be used when an integer variable is found to fall into a limited range of values, either through the use of source-level pragmas or through a compiler analysis, such as constant propagation. A concrete integer is specified by its size in bits, and can be signed or unsigned. WIL only supports concrete floating point representations, which can be specified as either single or double precision. Numeric values support a number of comparison and arithmetic operations in WIL.
WIL supports both abstract and concrete record representations. An abstract record is specified by using the keyword "Record", followed by a list of fields.
Record {class: class, x: Integer, y: Integer, z: Integer}
Figure 5: A example Record specification
Each field consists of an optional identifier, followed by the representation of the field. In addition the offset of the field in the record can be explicitly specified. Other than the constraints imposed by any declared offsets, the fields may be laid out in any order. A concrete record specification is almost identical, except for the substitution of the "Record" keyword with the "Structure" keyword. A concrete record implies that the ordering and offsets of the constituent fields is set. Record representations support creation, field access and update operations, among others.
WIL also supports a type of structural subtyping for record representations. Records can be only partially specified, listing only a subset of constituent fields. This is done by appending a ‘…’ to the end of the record specification, indicating that the other fields in the record are not important.
Record {class: class, x: Integer, y: Integer, ...}
Figure 6: A partially specified Record
Any record representations that contain these constituent fields can be considered a subtype of this specification, and can be used in place of it in the program. For example, the record specified in figure 5 is a subtype of the one specified in figure 6. This is useful in describing polymorphic variables and class hierarchies.
There are two types of concrete union representations in WIL. One is a conventional C-style union, specified similarly to a record, in that it consists of the "Union" keyword followed by a set of union members, each of which contains an optional identifier and a representation. In addition, WIL provides the ability to specify a discriminated union, which specifies a list of fields common to all members in the union, and also provides the ability to insert a runtime expression test to determine the layout of the rest of the value.
Record {class: class, x: Integer, y: Integer, ... }
where
{
when (class==2DPoint) => Record {class: class, x: Integer, y: Integer}
when (class==3DPoint) => Record {class: class, x: Integer, y:
Integer, z : Integer}
}
Figure 7: An example discriminated union
This will be useful for polymorphic variables, where the exact layout of a value can only be determined by a runtime test, determined here using a class equality test.
Arrays are specified by giving a size value, which can either be a fully abstract integer (which means the array is dynamically sized and needs to keep track of it's size), or as an integer constant or sub-range. This is followed by a specification of the representation of the individual array elements. Arrays support creation, element extraction and update, as well as size modification operations. Figure 7 shows the specification of an array of 50 elements, each of which is a pointer to a Record.
<Constant 50> *Record {class: class, x: Integer, y: Integer}
Figure 8: An example array specification
Pointers are specified by prepending a "*" to another representation, which indicates the layout of the underlying value. Valid operations on pointers include creation and dereference.
Representations can be concatenated by using the "::" concatenation operator, to indicate that the final representation is the concatenation of two other initial representations. In addition the "align" keyword can be used to specify the alignment requirements of a given value in memory. The "shared" keyword indicates a value may be thread shared, and places certain limitations on it's access and manipulation. Currently class and function values in WIL are specified as black-box primitives. A more detailed specification mechanism for such values is yet to be determined.
5. Representation Lowering and Optimization
The following figure depicts the proposed implementation of the representation choice and code generation process in Whirlwind.
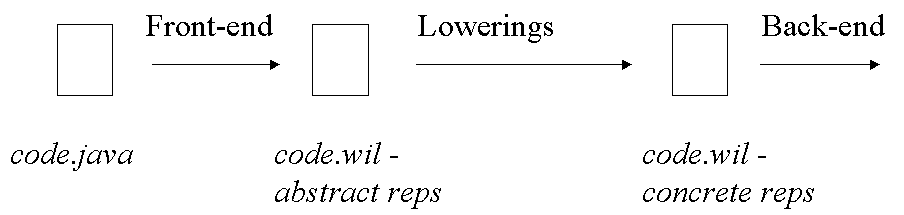
Figure 9: The representation lowering process
Initially a language specific front-end will compile the source program into a WIL textual file. Each variable, method parameter and return value will be annotated with an abstract representation as specified in the WIL syntax. This representation determines the operations possible on the given value, as well as the value's semantics for equality, assignment and allocation.

Figure 10: An example lowering
The first step in this sequence of lowerings chooses physical representations for each field in the record, choosing to represent both integers as signed 32 bit values. The ordering of the fields and their offsets remains unspecified. The next step lowers the Record to a Structure, specifying the order of the fields, as well as their offsets. This specification is now fully concrete, as it determines a concrete physical implementation for the value and all associated operations. The compiler back end can now generate code appropriate for the chosen physical representation.
These lowerings can be specified declaratively within the compiler as rewrite rules, allowing a simple way to express such transformations. For instance, one could write Record® Structure and Integer ® signed 32 bits as default rewrites. When lowering all operations on the original value must be lowered to operate on the more concrete value. For the default lowerings these transformations are often trivial, but in more complex cases these can be specified as rewrite rules as well.
The optimizer can use this framework to pursue layout optimizations by performing certain optimizing lowerings. In this case a representation is transformed into another potentially more efficient representation. An example of such a lowering is inlining, where a pointer representation is transformed to be inline, as in figure 11.
Record {x: *Integer, y: *Integer} ® Record {x: Integer, y: Integer}
Figure 11: An example of inlining
The fields of the record are no longer pointer references, and are now embedded in the record. As discussed earlier, the removal of pointer indirection can have significant performance benefits, reducing memory traffic and improving data locality. These types of lowerings can be specified as rewrite rules as well, for instance as *Integer® Integer. In this case operations on the value will have to be rewritten as well. For instance, in the case of the inlined fields in the record above, all operations such as *(r.x) will have to be rewritten as r.x, to eliminate the now unnecessary pointer dereference. It is intended that these transformations on operations also be specified internally as rewrite rules, allowing a fully declarative specification of such transformations. The rewrite rules will operate directly on the program intermediate representation, taking an initial parse tree and set of representations and transforming it into equivalent operations on transformed representations.
The policy decisions governing optimizing lowerings may be significantly different than for the default lowerings discussed earlier. Default lowerings such as Record->Structure are always meaning preserving, being able to support the semantics of all the operations possible on the original value. Additionally, these lowerings are generally applied uniformly across the program. On the other hand, optimizing lowerings are only applied at specific locations in the program, and do not always support all the operations possible on the original value. For example, in the inlining example above, the inlined fields can no longer safely be shared between two objects. For such reasons optimizing lowerings should only be applied where they are possible, safe and profitable.
n order for such an optimization to be possible, all uses of the value must be located so operations can be appropriately transformed. This can be a problem at a data flow merge point, where there can be a number of possible data sources for a value. In this case care must be taken to choose a representation at the merge point that is consistent with all incoming representations. This can be done in a number of ways. The easiest way is to choose a canonical boxed representation for the merge point, and require all data sources to convert their representation to this canonical version. These conversions are performed by special conversion operators in the WIL syntax. However it is not always possible to perform these conversions in place, and it may be unsafe to perform such conversions if the object is thread-shared. Another option is to insert a tag field into all incoming representations, and choose a discriminated union at the merge point. The code at the merge point can query this tag to determine the value’s specific representation, and operations can be performed appropriately. Alternatively the compiler could choose to specialize the code at the merge point for each possible incoming representation. The last two options both require that all incoming representations be known statically before compiling the merge point. When the merge point is a method invocation this will often require global inter-procedural program knowledge, requiring compilation to be delayed until link-time.
One problem with this approach involves polymorphism. At a polymorphic merge point only some subset of the fields of a value may be specified, representing the common fields of the receiver class. In this case the record will be specified with a ‘…’, as described earlier. In such situations all representation information about the non-shared fields may be lost. To handle such cases might require some notion of a default representation, to handle revealing such fields when there is no incoming representation information. Other options include insertion of a discriminated union or method specialization, both of which require global program knowledge and sophisticated data flow and alias information to determine all possible incoming representations to a particular receiver method. The details of how exactly to handle such situations is yet to be determined.
Another issue involves the safety of a particular optimization. Not all optimizations are guaranteed to be safe for all operations. For instance, in the case of inlining, it will generally not be safe to inline shared, mutable fields.
Figure 12: A shared field
If a shared object is inlined into multiple container objects, updates to the field through one container will not be reflected in the other copies. If the object is immutable it may still be safe to inline the object into all containers, since there will be no updates. However pointer equality tests between the copies will not yield correct results unless some extra information about object identity is maintained.
Information about the safety and possibility of representation optimizations may require sophisticated data flow analysis. Determining sharing relationships between objects requires detailed alias information, and finding all possible incoming representations for a particular receiver method may require a deep and expensive inter-procedural data flow analysis [6, 7]. Information about the potential benefits of a representation optimization can be guided by heuristics or detailed profile data. Another alternative is to allow source-level directives written by the programmer to guide representation optimizations. The WIL language provides syntax for source language front-ends to indicate desired optimizations by using the "® Rep" syntax.
decl a: Integer ® unsigned 16 bits;
Figure 13: Example of a "desired" representation choice
This source of this choice can be a source-level directive, or an a priori language wide implementation decision. The lowering process can interpret this directive either as an edict, in which case the desired transformation is guaranteed to be carried out, and no analysis to verify the correctness of the transformation will be performed, or as a recommendation, in which case the compiler will perform some analysis to ensure that the transformation will be safe and possible. The initial system will likely use source-level directives to guide representation optimization.
6. Examples of Representation Optimizations
There are a number of possible avenues for representation optimization that can hopefully be pursued using this framework. The Whirlwind representation specification language seeks to be as general as possible to allow easy experimentation with a variety of such techniques. Descriptions of a number of such opportunities follow.
One optimization that has already been discussed, and has been the topic of most of the related work in this area, is the automatic inlining and possible stack allocation of fields and local variables. Much of the related work in this area focuses on the "unboxing" of such values, and is described in a later section. As has already been mentioned, such transformations can provide sizable performance improvements in high-level languages such as Java and Smalltalk. In general it will be safe only to inline unshared or immutable fields and variables. In the case of shared, mutable objects, inlining a field or variable in a particular scope may violate the sharing semantics of the value. In addition, if a local variable is to be stack allocated, it must not be able to outlive the local scope.
Another possible optimization involves tagging schemes to support inlining of primitive types such as integers and booleans. In this approach integers are represented as a 31 bit value field, followed by a low order 1 bit tag field which is set to 1 (assuming 32 bit words). The integer value can easily be retrieved via a shift operation. Since the lower order bits of all pointers can be assumed to be set to zero (assuming memory is word aligned), this tag can be queried on all value accesses to see whether the value is a pointer to an arbitrary object or if it is an inline integer. Since integer values are immutable, this will not violate any sharing requirements.
rep TaggedValue := Structure {value: 31 bits, tag: 1 bit}
where
{
when (tag == 1) => Structure {value: signed 31 bits, tag: 1 bit}
when (tag == 0) => *Record {class : class, ... }
};
Figure 11: A representation for tagged integers
Conventional compiler optimizations and class analysis can remove unnecessary and redundant tag checks. By allocating more tag bits one can allow inlining of other primitive types as well.
Our framework also allows more efficient bit packing for values. For example it may not always be necessary for all integers to be allocated to full word size. Some integer variables can be statically determined to remain within a small sub-range of values, or be determined to be a compile time constant. In this case the optimizer may choose to allocate fewer (or zero) bits for these variables, since overflow will not be possible.
One can also use the representation optimization framework for more efficient encodings of header words. In languages where all values have a common header layout sometimes a more efficient encoding of this header information can be determined. The class field in Java, for example, is often represented by a full word. Since the number of classes in a program is usually not very large, this information can just as easily be encoded as a small integer. In such cases the language front-end can insert a language wide desired representation choice for all values specifying this encoding, and provide rewrite rules to transform all header operations.
Another possible optimization involves the design and implementation of cache conscious data structures. In pointer-based data models objects can often suffer from poor data locality, since the memory for a container object and the contents of its fields is allocated independently. This problem can often be remedied by inlining the constituent fields, as described earlier. In cases where inlining is not safe, care can be taken to ensure that the object and its contents are at least allocated in the same cache line [4]. This can potentially be done by choosing a representation whose creation operation takes cache organization into account when performing memory allocation.
Most related work in layout optimizations is generally finely tuned to allow only some subset of the possibilities found in the proposed Whirlwind system. Whirlwind intends to provide as general a framework as possible, to allow future experimentation with layout optimizations that are not currently envisioned. Since this field is relatively unexplored, it is hoped that by providing such a general mechanism for representation specification more opportunities will eventually be discovered.
7. Related Work
A number of other projects have sought to address some subset of these deficiencies in higher level programming languages. Most of these systems lack the generality of Whirlwind’s approach and are not suitable for object-oriented programming languages, but provide valuable insights into the possible benefits of such systems. All of these projects focus either on the problem of layout optimization or on the problem of general representation specification.
Leroy has developed a system for ML that automatically unboxes data values in monomorphic stretches of the program, automatically generating code that operates on the unboxed representation where possible [10]. (An unboxed value is one that is represented inline, while a boxed value refers to a high-level pointer-based value as described earlier.) Leroy inserts conversions between boxed and unboxed versions at transitions between polymorphic and monomorphic sections of the code, relying on the ML type inference mechanism to determine these boundaries. The efficiency of this approach is enhanced by increasing the sections of code where values are monomorphic, using inlining and related techniques. These ideas were implemented by Shao and Appel, also supporting modules and making efficiency improvements in Leroy’s work [13]. These approaches are strictly less general than Whirlwind’s approach, as it addresses only one possible representation optimization opportunity, albeit a ubiquitous one. It is also unclear how this approach could apply to object-oriented or dynamically typed languages, as it relies on ML’s specialized type inference mechanism. However these implementations show the possible power in layout optimization, as Shao’s compiler displayed speedups of up to 19% over code that did not perform unboxing optimizations.
The TIL ML compiler explores another way to handle the restrictions imposed by polymorphism on data representation [14]. Their approach, called intensional polymorphism, constructs types at runtime, which are passed as values to polymorphic functions. These functions can then branch based on the type, accessing the value as appropriate to the given type. The construction and querying of the type information will make polymorphic code larger and slower, making it important to maximize the amount of monomorphic code, where the value can be accessed directly. Thus TIL relies on inlining, aggressive loop optimizations and other optimization opportunities to minimize polymorphism. In addition, TIL is able to use intensional polymorphism to provide nearly tag free garbage collection. TIL suffers from many of the same drawbacks as Shao and Leroy's work on optimizing data representation in ML. TIL is also heavily dependent on the ML type inference system to determine polymorphic sections of code. This requires the TIL compiler to maintain type information through all stages of compilation. Also, the TIL system is only able to make global representation optimizations, and is unable to use specialized representations in certain critical regions of the program. The Whirlwind approach can be seen as both more efficient and more general than TIL's approach.
Dimock proposes an approach that is able to choose specialized representations for particular flow paths in a program [5]. In this system, producers of values are labeled as sources, and are annotated with a list of possible consumers of that value. Similarly, consumers are labeled as sinks, and are annotated with a list of possible sources. Separate representation choices can generally be made independently for each path from source to sink. This system is able to handle polymorphism by introducing an implicit tagging scheme when one sink can be reached by several possible flow paths, each of a different representation. This tag can be queried at runtime to determine the actual representation. In addition, when one producer is the source for several flow paths of different representation, the system is able to produce a tuple of values, one for each flow path. It is unclear how this system would maintain correctness in an imperative program with mutable state, requiring the values in the tuple to remain mutually consistent. This system is as yet unimplemented, and describes only a limited example using function representation. It lacks a full representation specification language like WIL. It is an improvement over previous systems in the ability to do a larger amount of static reasoning about representations.
Quiennec develops an elegant model for the explicit description of data aggregates, and for the utilization of this information in generating code for the allocation, initialization and access of these aggregates [11, 12]. He is able to describe a rich library of possible representation types starting with a small subset of primitive types, including characters, references and numeric values. Each of these primitive data types need only provide methods for the access and modification of their data. Aggregate representations of arbitrary depth are allowed by composing previous types. Each type of aggregate need only define five functions, the S, N, D, A and I functions. The S function determines the size of a given type, the N function returns the number of subparts of the given type and the D function returns the offset within the type of the jth subpart. In addition, the A and I functions determine the necessary allocation size and provide for the initialization of a new instance of the type, given a list of integers as allocation parameters. These functions are sufficient to fully describe the allocation, initialization and access of new instances of these representations, and are used to generate code for such. By defining these five functions Quiennec is able to describe the common Cartesian Product, Cartesian Power and Kleene Star data types, which represent records, fixed length and dynamic length arrays respectively. In addition, he shows how one can describe new aggregate types, such as variants, using this framework. Quiennec goes on to show how garbage collection, data inspection and other facilities can be easily incorporated into this framework by adding new functionality to the created data types.
Quiennec’s system is primarily a tool for describing arbitrary structuring of data types to form aggregate representations, and to easily generate code to manipulate values of such representations. He does this by providing the described procedural interface to describing representations. He does not explore the possibility of using his framework to perform representation optimizations such as inlining and arbitrary encoding. However, one could imagine how his system could easily be extended, possibly by being able to add user defined primitive types and conversions between them, to allow a fairly broad range of such optimizations. Also, his system shares TIL’s requirement of retaining explicit structure information at runtime. This type information must be queried (using the 5 functions described above) to allow allocation and access of structured values during program execution. Performance is maintained by performing aggressive partial evaluation and common subexpression elimination, so that all computations that depend only on data constants or static type information are eliminated at compile time. Whirlwind’s proposed system chooses to generate the code to manipulate values at compile time, removing the need to maintain structural information at run-time, with no perceived loss in flexibility. Quiennec’s system also does not appear to be currently implemented.
The SchemeXerox compiler built on Quiennec’s work by implementing a similar framework to describe its data representations and primitive data types. It also provides a declarative interface to representation specification, which is internally converted to a procedural specification similar to Quiennec’s. The SchemeXerox compiler also provides a distinction between a structure’s type (i.e. what operations are possible upon it), and its layout (i.e. its physical representation), which may allow representation optimizations such as inlining and encoding. There are also further levels of more detailed structural information that is internal to the compiler. This is similar to WIL’s notion of abstract and concrete representations. The SchemeXerox compiler’s representation specification system does not match the generality of WIL; it supports only a subset of the representation optimizations possible in WIL, and is not able to support arbitrary user defined tagging schemes. It also shares necessity of Quiennec’s model to maintain detailed structural information at runtime.
Dolby presents a system that performs automatic inlining of child objects within containers in the context of an imperative object-oriented language (a modified version C++ that has a reference based data model) [6, 7]. He is able to do this by doing a sophisticated data flow analysis that determines the safety and possibility of inlining a field. This analysis generates alias information that is able to determine precise sharing relationships between objects, by tracking data flow through fields. This allows determination of whether or not a component object is unshared and can be inlined. His system does not pursue inlining of immutable objects. This analysis also allows a precise determination of the possible sources of a data value, allowing code generation for all possible incoming representations. This is performed by splitting the data paths from different source representations to uses, similarly to Dimock’s system. He investigates a variety of iterative data flow analyses of increasing power in their ability to generate the necessary information to perform inlining. He finds that an inter-procedural analysis with adaptive context sensitivity is necessary to achieve significant performance gains at realizable cost. A straightforward fixed depth context sensitive inter-procedural analysis would require more levels than would be computationally feasible, and an intra-procedural analysis would fail to discover many important inlining opportunities. Using the adaptive approach his system is able to achieve a runtime improvement of up to 50%, with an average benefit for 10%, solely from inlining optimizations.
Dolby’s work is the first significant effort at performing layout optimizations in imperative object-oriented programming languages. His work displays the potential for performance gains possible from such optimizations, and shows that the analyses required to perform such optimizations, while sophisticated and expensive, are feasible. However his system only explores one possible optimization in the context of one high-level source programming language. Our system hopes to explore a variety of possible optimizations for a variety of source languages.
8. Conclusion
The WIL intermediate language is a flexible and powerful target language for translation from a variety of object-oriented source languages. Its versatility will seek to facilitate the rapid construction of language specific front-ends, as well as provide more information to the optimizer to pursue new and aggressive optimization opportunities. In addition it provides the ability to explicitly specify representation choices, which can be used to implement source directed and automatic layout optimizations. This framework will provide a simple declarative interface to specify representation lowering and optimization, expressing both as rewrite rules from source to target code. The simplicity and generality of this system will hopefully allow experimentation with a variety of possibly beneficial layout optimizations.
In contrast to previous work, this system allows expression of representation specification and optimization in a language independent framework. This proposed system will be the first to my knowledge to use a general framework of representation specification to pursue interesting representation optimizations. This allows a variety of language specific front-ends to write to a common intermediate language, specifying representations at a level of concrete-ness appropriate for the language. Obviously a front-end for a lower level language like C++ may choose to specify representations concretely, while higher level languages can choose more abstract representations. This allows the optimizer to pursue representation optimizations in a language independent manner. In addition, the ability for the language specific front-end to specify desired optimizations allows optimized layouts finely tuned for a particular high-level language’s data model.
9. Project Status and Future Work
A preliminary design for the WIL intermediate language, including the representation specification language as a subset, has been designed, and a parser for this language has been implemented. A framework for the representation lowering and optimization process has been developed, and some possible layout optimizations have been investigated.
Work will continue on the rest of the Whirlwind infrastructure, including implementation of language front-ends, design and implementation of an internal intermediate representation, the representation lowering and optimization framework as well as back ends for output to assembly or C source code. The syntax of the rewrite rules used to express representation lowering is yet to be fully designed, although some prototype designs exist. These rewrite rules will likely be expressed over paths of representation lowerings, allowing more specificity in their application. The design of the syntax used to specify these rules will be guided by current graph rewrite systems found in the literature [2, 15].
Once this framework in place, experimentation with alternate representation choices can begin. Initially these choices will be guided by source-level directives inserted by the user for efficiency concerns. These choices may be verified for safety by a global representation checker. Eventually the hope is to develop compiler analyses and profiling techniques that allow automatic layout optimizations by determining the safety, possibility and profitability of various optimizations. Eventually optimizations may be interleaved with additional default lowering phases, hopefully exposing more opportunities for optimization. It is hoped that such work will expose many previously unexplored areas of program optimization research.
Another area of future work lies in more modular approaches to handling representation choices at merge points, as described earlier. Currently several proposed solutions to this problem require whole program knowledge, which precludes separate compilation of libraries and files. A modular approach to this problem would allow separate compilation, as well as amortize optimization cost across compilation and linking. It is hoped that layout optimization can be fit into Whirlwind’s generalized notion of staged compilation, which allows each stage of compilation (separate, link-time and run-time) to perform whatever optimizations are possible at that point, and delay others for later stages [3]. This model also allows all stages of compilation to share a common pool of information that can be used to guide optimization and compilation.
This work may also aid in the description and implementation of new data types and models in high-level languages. The rewrite framework for representation lowering provides a simple declarative interface for describing the process of code generation. Eventually this process may lower all objects all the way down to bit level representations, allowing very easy back-end code generation. This may also allow simple specification of new data models at the meta-level within the compiler, allowing simple code generation for new data types without widespread modification to the source code. For example a high-level language can introduce primitive object types that explicitly support distribution by providing new abstract types, operations and transformations for global and local objects that implement the various mobility primitives. It may also be possible to specify other simple program optimizations, such as common sub-expression elimination, as rewrite rules [2, 15].
Acknowledgements
I would like to thank my advisor, Craig Chambers, for his invaluable guidance and support in this project. I would also like to thank Mike Ernst, who contributed to early versions of the representation specification language, and the rest of the Cecil group, for not falling asleep when I talked about this during our group meetings.
Bibliography
[1] Adams, Norman, Pavel Curtis and Mike Spreitzer, "First-class Data-type Representations in SchemeXerox", PLDI 1993, pp 139-146.
[2] Assmann, Uwe, "How to Uniformly Specify Program Analysis and Transformation with Graph Rewrite Systems", in Compiler Construction 1996, Lecture Notes in Comp. Sci. 1060, Springer Publishers, Linkoeping, Germany, 1996.
[3] Chambers, Craig, "Whirlwind Project Proposal", draft, September 1998.
[4] Chilimbi. Trishul, "Cache-Conscious Data Structures", Talk at Microsoft Research, 1999.
[5] Dimock, Allyn, Robert Muller, Franklyn Turbak, J.B. Wells, "Strongly Typed Flow-Directed Representation Transformation", ICFP 1997, pp 11-23.
[6] Dolby, Julian, "Automatic Inline Allocation of Objects", PLDI 1997.
[7] Dolby, Julian, "An Evaluation of Automatic Object Inline Allocation Techiniques", OOPSLA 1998.
[8] Ernst, Michael, Craig Kaplan and Craig Chambers, "Predicate Dispatch: A Unified Theory of Dispatch", ECOOP 1998, pp. 186-211.
[9] Jones, Simon Peyton and Norman Ramsey, "Machine-Independent Support for Garbage Collection, Exception Handling and Concurrency", draft, August 1998.
[10] Leroy, Xavier, "Unboxed objects and polymorphic typing", POPL 1992, pp. 177-188.
[11] Quiennec, Christian and Pierre Cointe, "An Open Ended Data Representation Model for EU_LISP", LFP 1988, pp. 298-308.
[12] Quiennec, Christian, "A Specification Framework for Data Aggregates", unnumbered technical report from Laboratoire d’Informatique de l’Ecole Polytechnique, 1989.
[13] Shao, Zhong and Andrew W. Appel, "A Type-Based Compiler for Standard ML", PLDI 1995, pp.116-129.
[14] Tarditi, D., G. Morrisett, P. Cheng, C. Stone, R.Harper and P.Lee, "TIL: A Type-Directed Optimizing Compiler for ML", PLDI 1996, pp. 181-192.
[15] Visser, Eelco, Zine-el-Abidine Benaissa and Andrew Tolmach, "Building Program Optimizers with Rewriting Strategies", ICFP 1998.